안녕하세요 진자이입니다 :) 이번 포스팅에서는 '데이터 분석을 위한 SQL 레시피' 책의 일부 내용을 정리해보고자 합니다. 미들웨어는 PostgreSQL 기준으로 작성되었으며, 테이블 조작에 대한 내용을 다룹니다.
OVERVIEW : 테이블 조작
- (단일) 그룹 특징 잡기 - 집약 함수 / GROUP BY / 윈도 함수 / OVER(PARTITION BY~)
- (단일) 그룹 내부 순서 - 윈도 함수 / OVER(ORDER BY ~) / OVER(ROWS ~)
- (단일) 카테고리 상위 N개 출력하기
- (단일) 세로 기반 데이터를 가로 기반 변환 - MAX(CASE~) / string_agg / listagg / collect_list
- (단일) 가로 기반 데이터를 세로 기반 변환 - unnest / explode / cross join / lateral view / regexp_split_to_table
- (다중) 여러 개의 테이블을 세로로 결합 - UNION ALL
- (다중) 여러 개의 테이블을 가로로 정렬 - LEFT JOIN / 상관 서브 쿼리
- (다중) 조건 플래그를 0과 1로 표현 - CASE / SIGN
- (다중) 계산한 테이블에 이름 붙여 재사용 - WITH ~
(단일) 그룹 특징 잡기

상품 평가(review) 테이블에서 집약 함수를 사용하는 방법부터 알아보자.
SELECT
C0UNT(*) AS total_count -- 모든 행의 개수
,COUNT(DISTINCT user_id) AS user_count -- 중복 제외한 user-id 개수
, COUNT(DISTINCT product_id) AS product_count -- 중복 제외한 product-id 개수
,SUM(score) AS sum -- 합계
,AVG(score) AS avg -- 평균
,MAX(score) AS max -- 최대
,MIN(score) AS min -- 최소
FROM
review
-- 집단 별로 정보를 확인하고 싶으면 아래 GROUP BY를 사용한다
-- GROUP BY user_id
;GROUP BY를 사용할 때는 지정한 컬럼을 유니크 키로 새로운 테이블을 만든다. 따라서, 집약 함수를 적용한 값과 집약 전의 값은 동시에 사용할 수 없다. 그렇다면, 집약 전과 집약 후의 값을 동시에 다룰 때는 어떻게 해야할까?
윈도 함수를 사용해서 개별 리뷰 점수와 평균 리뷰 점수의 차이를 구하는 쿼리를 만들어보자.
SELECT
user_id
,product_id
-- 개별 리뷰 점수
,score
-- 전체 평균 리뷰 점수
,AVG(score) 0VER() AS avg_score
-- 사용자의 평균 리뷰 점수
,AVG (score) OVER(PARTITION BY user_id) AS user_avg_score
-- 개별 리뷰 점수와 사용자 평균 리뷰 점수의 차이
,score - AVG(score) 0VER(PARTITI0N BY user_id) AS user_avg_score_diff
FROM
review
;
(단일) 그룹 내부 순서

인기 상품(popular_products) 테이블로 그룹의 내부 순서를 적용하는 쿼리를 만들어보자. 첫 번째로, 윈도 함수의 ORDER BY 구문을 사용해 테이블 내부의 순서를 다루는 쿼리를 만들어보자.
SELECT
product_id
,score
-- 점수 순서로 유일한 순위를 붙임
,ROW_NUMBER() OVER(ORDER BY score DESC) AS row
-- 같은 순위를 허용해서 순위를 붙임
,RANK() OVER(ORDER BY score DESC) AS rank
-- 같은 순위가 있을 때 같은 순위 다음에 있는 순위를 건너 뛰고 순위를 붙임
,DENSE_RANK() OVER(ORDER BY score DESC) AS dense_rank
-- 현재 행보다 앞에 있는 행의 값 추출하기
,LAG(product_id) OVER(ORDER BY score DESC) AS lagl
,LAG(product_id, 2) OVER(ORDER BY score DESC) AS lag2
-- 현재 행보다 뒤에 있는 행의 값 추출하기
,LEAD(product_id) OVER(ORDER BY score DESC) AS leadl
,LEAD(product_id, 2) OVER(ORDER BY score DESC) AS lead2
FROM popular_products
ORDER BY row
;
ORDER BY 구문과 집약 함수를 조합하여 적용 범위를 유용하게 지정해보자.
SELECT
product_id
,score
-- 점수 순서로 유일한 순위를 붙임
,ROW.NUMBER() OVER(ORDER BY score DESC) AS row
-- 순위 상위부터의 누계 점수 계산하기
,SUM(score)
OVER(ORDER BY score DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS cum_score
-- 현재 행과 앞 뒤의 행이 가진 값올 기반으로 평균 점수 계산하기
,AVG(score)
OVER(ORDER BY score DESC
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)
AS local.avg
-- 순위가 높은 상품 ID 추출하기
,FIRST_VALUE(product_id)
OVER(ORDER BY score DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
AS first_value
-- 순위가 낮은 상품 ID 추출하기
,LAST_VALUE(product_id)
OVER(ORDER BY score DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
AS last.value
FROM popular_products
ORDER BY row
;* 윈도 프레임 지정은 현재 레코드 위치를 기반으로 상대적인 윈도 정의.
* 기본 구문 : ROWS BETWEEN start AND end 이며 start end에는 다음과 같은 키워드가 온다.
- CURRENT ROW : 현재 행
- n PRECEDING : n행 앞
- n FOLLOWING : n행 뒤
- UNBOUNDED PRECEDING : 이전 행 전부
- UNBOUNDED FOLLOWING : 이후 행 전부
PARTITION BY과 ORDER BY를 조합하여 카테고리의 순위를 계산하는 쿼리는 다음과 같다.
SELECT
category
,product_id
,score
-- 카테고리별로 점수 순서로 정렬하고 유일한 순위를 붙임
,ROW-NUMBER()
0VER(PARTITI0N BY category ORDER BY score DESC)
AS row
-- 카테고리별로 같은 순위룔 허가하고 순위를 붙임
,RANK()
OVER(PARTITION BY category ORDER BY score DESC)
AS rank
-- 카테고리별로 같은 순위가 있을 때 같은 순위 다음에 있는 순위를 건너 뛰고 순위를 붙임
,DENSE_RANK()
0VER(PARTITI0N BY category ORDER BY score DESC)
AS dense_rank
FROM popular_products
ORDER BY category, row
;
(단일) 각 카테고리 상위 N개 추출
먼저, 위와 같은 테이블을 이용하여 각 카테고리들의 순위 상위 2개까지 상품을 추출하는 쿼리를 만들어보자. 이때, 윈도 함수를 WHERE 문에 사용할 수 없으므로, SELECT 구문에서 윈도 함수를 사용한 결과를 서브 쿼리로 만든 뒤 외부에서 WHERE 구문을 적용해야 한다.
SELECT *
FROM
-- 서브 쿼리 내부에서 순위 계산하기
(SELECT
category
,product_id
,score
-- 카테고리별로 점수 순서로 유일한 순위를 붙임
,ROW_NUMBER()
0VER(PARTITI0N BY category ORDER BY score DESC)
AS rank
FROM popular_products
)AS popular_products_with_rank
-- 외부 쿼리에서 순위 활용해 압축하기
WHERE rank <= 2
ORDER BY category, rank
;
카테고리별 순위 최상위 상품을 추출하는 쿼리도 만들어보자. 이때는 SELECT DISTINCT와 FIRST_VALUE를 사용해서 간단히 추출할 수 있다.
-- DISTINCT 구문을 사용해 중복 제거하기
SELECT DISTINCT
category
-- 카테고리별로 순위 최상위 상품 ID 추출하기
,FIRST_VALUE(product_id)
OVER(PARTITION BY category ORDER BY score DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
AS product_id
FROM popular_products
;
(단일) 세로 기반 데이터를 가로 기반 변환

날짜별 KPI 데이터 테이블(daily_kpi)에서 날짜별로 impression, sessions, users라는 지표의 추이를 쉽게 볼 수 있게 열로 전개하는 쿼리를 만들어보자.
SELECT
dt
,MAX(CASE WHEN indicator = 'impressions' THEN val END) AS impressions
,MAX(CASE WHEN indicator = 'sessions' THEN val END) AS sessions
,MAX(CASE WHEN indicator = 'users' THEN val END) AS users
FROM daily_kpi
GROUP BY dt
ORDER BY dt
;
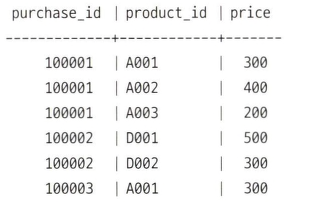
구매 상세 로그 테이블(purchase_detail_log)에서 행을 쉼표로 구분한 문자열로 집약하는 쿼리를 string_agg 라는 함수를 사용해서 만들어보자.
SELECT
purchase_id
-- 상품 ID를 배열에 집약하고 쉼표로 구분된 문자열로 변환하기
,string_agg(product_id,',') AS product_ids
FROM purchase_detail_log
GROUP BY purchase_id
ORDER BY purchase_id
;
(단일) 가로 기반 데이터를 세로 기반 변환
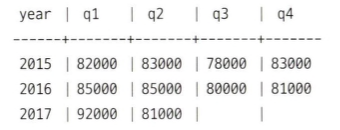
4분기 매출 테이블이 다음과 같이 구성돼 있다고 하자(데이터의 수는 고정) 데이터 수와 같은 수의 일련 번호를 가진 피벗 테이블을 만들고 CROSS JOIN하자.
SELECT
q.year
-- Ql에서 Q4까지의 레이블 이름 출력하기
,CASE
WHEN p.idx = 1 THEN 'ql',
WHEN p.idx = 2 THEN 'q2',
WHEN p.idx = 3 THEN 'q3',
WHEN p.idx = 4 THEN 'q4',
END AS quarter
-- Ql에시 Q4까지의 매출 출력하기
,CASE
WHEN p.idx = 1 THEN q.ql
WHEN p.idx = 2 THEN q.q2
WHEN p.idx = 3 THEN q.q3
WHEN p.idx = 4 THEN q.q4
END AS sales
FROM
quarterly.sales AS q
CROSS JOIN
-- 행으로 전개하고 싶은 열의 수만큼 순번 테이블 만들기
( SELECT 1 AS idx
UNION ALL SELECT 2 AS idx
UNION ALL SELECT 3 AS idx
UNION ALL SELECT 4 AS idx
)AS p
;

이번엔 구매 로그(purchase_log) 테이블로 데이터의 수가 고정되지 않은, 임의의 길이를 가진 배열을 행으로 전개해보자.
SELECT
purchase_id
,product_id
FROM
purchase_log AS p
-- string_to_array 함수로 문자열을 배열로 변환하고, unnest 함수로 테이블로 변환하기
CROSS JOIN unnest(string_to_array(product_ids, AS product_id
;
(다중) 여러 개의 테이블을 세로로 결합

결합할 때는 테이블의 컬럼이 완전히 일치해야 하므로, 한쪽 테이블에만 존재하는 컬럼은 SELECT 구문으로 제외하거나 디폴트 값으로 지정해야 한다.
SELECT 'appl' AS app_name, user_id, name, email FROM appl_mst_users
UNION ALL
SELECT 'app2' AS app.name, user_id, name, NULL AS email FROM app2_mst_users;
(다중) 여러 개의 테이블을 가로로 정렬



가장 상단 부터 카테고리 마스터 테이블(mst_categories), 카테고리별 매출(category_sales), 카테고리별 상품 매출 순위(product_sale_ranking) 테이블이다. 이들을 결합하는 쿼리를 만드는데, 마스터 테이블 행 수를 변경하지 않고 여러 개의 테이블을 가로로 정렬해보자.
SELECT
m.category_id
,m.name
,s.sales
,r.product_id AS top_sale_product
FROM
mst_categories AS m
-- LEFT JOIN을 사용해서 결합한 레코드를 남김
LEFT JOIN
-- 카테고리별 매출액 결합하기
category.sales AS s
ON m.category_id = s.category_id
-- LEFT JOIN을 사용해서 결합하지 못한 레코드를 남김
LEFT JOIN
-- 카테고리별 최고 매출 상품 하나만 추출해서 결합하기
product.sale.ranking AS r
ON m.category_id = r.category_id
AND r.rank = 1
;
JOIN을 사용하지 않고 상관 서브쿼리로 여러 개의 테이블을 가로로 정렬하는 쿼리는 다음과 같다. 이때, ORDER BY 구문과 LIMIT 구문을 사용했다는 것에 초점을 두고 확인해보자.
SELECT
m.category_id
,m.name
-- 상관 서브쿼리를 사용해 카테고리별로 매출액 추출하기
,(SELECT s.sales
FROM category.sales AS s
WHERE m.category_id = s-category_id
)AS sales
-- 상관 서브쿼리를 사용해 카테고리별로 최고 매출 상품을 하나 추출하기(순위로 따로 압축하지 않아도 됨)
,(SELECT r.product_id
FROM product_sale_ranking AS r
WHERE m.category_id = r.category_id
ORDER BY sales DESC
LIMIT 1
)AS top_sale_product
FROM
mst.categories AS m
;
(다중) 조건 플래그를 0과 1로 표현
여러 개의 테이블을 가로로 정렬하는 방법을 응용해서 마스터 테이블에 다양한 데이터를 집약하고, 마스터 테이블의 속성 조건을 0 또는 1이라는 플래그로 표현해보자.


왼쪽은 신용카드 번호를 포함한 사용자 마스터(mst_users_with_card_number) 테이블이며, 오른쪽은 구매 로그 테이블이다.
CASE 식과 SIGN 함수로 신용카드 등로고가 구매 이력 유무를 0과 1이라는 플래그로 나타내는 쿼리이다.
SELECT
m.user_id
,m.card_number
,COUNT(p.user_id) AS purchase_count
-- 신용 카드 번호를 등록한 경우 1, 등록하지 않은 경우 0으로 표현하기
,CASE WHEN m.card_number IS NOT NULL THEN 1 ELSE 0 END AS has_card
-- 구매 이력이 있는 경우 1, 없는 경우 0으로 표현하기
,SIGN(COUNT(p.user_id)) AS has_purchased
FROM
mst_users_with_card_number AS m
LEFT JOIN
purchase.log AS p
ON m.user_id = p.user_id
GROUP BY m.user_id, m-card.number
;
(다중) 계산한 테이블에 이름 붙여 재사용
비슷한 처리를 여러번 하거나, 서브 쿼리의 중첩이 많아질 경우 공통 테이블 식(CTE : Common Table Expression)을 사용하여 일시적인 테이블에 이름을 붙여 재사용해보자

카테고리별 상품 매출(product_sales) 테이블에서 카테고리별 순위를 윈도 함수로 추가하고 테이블의 이름을 붙여보자. (WITH <테이블명> AS (SELECT ~) 구문을 사용하자.
WITH
product_sale_ranking AS (
SELECT
category.name
,product_id
,sales
,ROW_NUMBER() 0VER(PARTITION BY category_name ORDER BY sales DESC) AS rank
FROM
product_sales
)
SELECT *
FROM product_sale_ranking
;
유니크한 순위 목록을 계산하는 쿼리도 만들어보자.
WITH
product_sale_ranking AS (
SELECT
category.name
,product_id
,sales
,ROW_NUMBER() 0VER(PARTITION BY category_name ORDER BY sales DESC) AS rank
FROM
product_sales
)
,mst_rank AS (
SELECT DISTINCT rank
FROM product_sale_ranking
)
SELECT *
FROM mst_rank
;
'DATA' 카테고리의 다른 글
| Python 크롤링 B to P (1) | 2024.01.31 |
|---|---|
| [SQL] PostgreSQL 값 조작 (0) | 2023.08.04 |
| [SQL] MySQL yalco 강의 정리 (2) 서브쿼리/JOIN/UNION 총 정리 (0) | 2023.07.22 |
| [SQL] MySQL yalco 강의 정리 (1) SELECT 기능(연산자/함수) 총 정리 (0) | 2023.07.22 |
| [SQL] 인프런 Do it! SQL 입문 정리 (5) - 주식 분석 (0) | 2023.07.19 |



