Python 크롤링 B to P
안녕하세요 진자이입니다 :) 이번 포스팅에서는 Python을 활용한 크롤링에 대한 B to P를 기록해보겠습니다! A to Z가 아니라 B to P 인 이유는 정리한다고 노력하긴 했으나, 부족한 내용이 있을 수 있고 최대한 정확한 정보를 기재하려고 노력했으나 오류가 있을 수 있다는 점을 양해부탁드리고자 .. 이렇게 이름을 지어보았습니다.
크롤링(Crawling)이란? + 스크래핑(Scraping)과 차이?
크롤링은 crawl, '기다'라는 뜻의 영어 단어에서 파생된 단어이며 웹 페이지(인터넷)에서 정보를 수집하거나 그대로 가져와서 데이터를 추출해 내는 행위를 일컫는다. 스크래핑과 혼용되어 사용되기도하는데, 약간의 차이가 존재한다. 크롤링은 웹을 기반으로 작동하며 웹사이트에 대한 정보를 색인화하고 저장되며, 스크래핑은 웹을 비롯한 다양한 소스에서 데이터를 추출한다.
무슨 차이인지 모를 수도 있겠다. 쉽게 생각하면 "타겟 웹 페이지의 유무"와 "중복 제거 실행" 인데, 웹 크롤링은 타겟 웹 페이지가 없고 중복 제거를 실행하며 스크래핑은 반대라고 생각하면 된다. 검색엔진을 사용해서 탐색을 먼저하고 정보를 가져오는 방식이다. 이에 반해 스크래핑은 목표로 하는 특정 페이지가 있는 것이고 중복 제거가 필수가 아니다. 필요한 정보만 가져오는 것이다. 따라서, 웹 크롤링은 대규모의 데이터 수집에 활용이되고, 스크래핑은 소규모의 데이터 수집에 활용된다고 생각하면 되겠다.
그렇다면, 크롤링과 크롤러, 스크래핑과 스크래퍼는 무슨 차이일까? 쉽게, 크롤링이라는 행위를 하는 소프트웨어(혹은 프로그램), 스크래핑 행위를 하는 소프트웨어(프로그램)을 스크래퍼라고 한다.
앞서 얘기했듯이 이 두 개의 개념은 혼용하여 사용한다. 아래 코드에서 HTML의 tag를 이용해서 정보를 추출할 건데, 이건 엄연히 말하면 크롤러이 아니라 스크래퍼인 것이다. 하지만, 편의 상 여기서부터는 모두 크롤링이라고 지칭하며 크롤링이냐, 스크래핑이냐의 판단은 해당 글로 충분히 파악할 수 있을거라고 생각한다.
크롤링, 왜 하는 걸까?

전국의 동물병원 위치와 세부 정보를 파악하기 위해 국가동물보호정보시스템의 동물병원 정보를 찾았고 지도에 시각화를 하거나, 소재지를 통해 지역별 현황을 파악해보고 싶다. 그렇다면 csv 혹은 excel 파일로 저장을 해야 하는데, 아무리 찾아도 그런 버튼이 보이지 않는다. 그럼 하나씩 복사, 붙여넣기 하면서 정보를 얻어내야 할까?
아니다. 우리는 크롤러를 작동하여 쉽고 빠르게 해당 정보를 정리할 수 있다. (비단, 해당 경우 뿐만 아니라도 웹 페이지의 정보를 긁어오고 싶을 때 크롤링을 사용한다.)
크롤링의 문제점, 주의사항
2023년 2월, 부동산 정보 플랫폼 직방이 스타트업인 방픽과 크롤링에 관련한 법적 논쟁에서 승소했다. 방픽은 크롤링을 활용해 여러 부동산 플랫폼에 등록돼 있는 매물 정보를 한 곳에 모아 제공을 하는 서비스였는데, 법원은 직방의 매물 정보를 DB에 해당하며 방픽이 데이터베이스권을 침해한 것에 대해 엄격하게 판단한 것이다. 해당 사례 외에도 잡코리아와 사람인, 야놀자와 여기어때 등 크롤링과 관련하여 다양한 법적 사례가 존재하니 한 번 찾아보길 바란다.
그럼, 대체 어느 정도가 문제가 될까? 상업적으로 이용할 게 아니더라도 크롤링을 해도 되는가?
일반적으로 통용되는 문제가 되는 크롤링은 다음과 같다. (1) 수집한 데이터의 상업적 이용 (2) 크롤링 과정에서의 서버 문제에 영향 (3) 민감한 정보 (4) 사이트 이용방침을 위반.
가장 정확한 정보는 해당 웹 사이트에서 제시하는 약관이다. 모든 웹 사이트는 자동화 프로그램에 대한 규제 여부를 명시하며 robots.txt라는 파일로 해당 정보를 파악할 수 있는데, 웹 사이트 URL 뒤에 '/robots.txt'를 붙이는 것만으로도 쉽게 확인할 수 있다. 하지만, 파악할 수 없는 경우도 있으니 약관을 살피는 등의 다른 경우를 찾아서라도 꼭! 해당 규제에 대한 정보를 파악하자.
크롤링에 대한 배경을 알아봤으니, 이제 정적 크롤링과 동적 크롤링에 대해서 본격적으로 알아보자!
정적 크롤링과 동적 크롤링
크롤링은 크게 두 가지로 구성된다. 정적 크롤링과 동적 크롤링. 정적 크롤링은 한 페이지 안에서 원하는 정보가 모두 드러나는 정적 데이터를 수집할 때 사용되며, 동적 수집은 입력/클릭/로그인 등과 같이 페이지 이동이 있어야 보이는 동적 데이터를 수집할 때 활용한다. 관련해서 내용을 조금 더 정리하면 다음과 같다.
정적 크롤링 : 서버에 미리 저장된 파일이 그대로 전달되는 웹페이지에 사용한다. 웹 페이지의 URL 주소만 주소창에 입력하면 웹 브라우저로 HTML 정보 수집이 가능하다. HTML을 requests 혹은 urllib 패키지를 통해 가져온 후 주로 BeautifulSoup 패키지로 파싱하여 원하는 정보를 수집한다. 수집 속도는 동적 크롤링에 비해 빠른 편이며 페이지에 대한 별도의 조작이 필요하지 않다. 예시로는 네이버 검색 결과 수집이 있을 수 있다.
동적 크롤링 : URL만으로는 들어갈 수 없는 웹 페이지나, 들어가지더라도 내용이 계속 추가되거나 수정되는 웹에 대해서 정보를 수집한다. 주로 Selenium 패키지로 chromedriver를 제어하여 수집하며, 정적 크롤링에 비해 속도가 느리다는 단점이 있다. (BeautifulSoup를 사용하기도 한다) 예시로는 로그인을 해야 접속가능한 네이버 메일, 드래그를 아래로 내려 새로운 영상이 계속 추가되는 인스타그램 해시태그 수집 등이 있다.
HTML에 대해서 조금 배워보자.
잠깐, 갑자기 HTML이 왜 나오지?
라는 생각을 할 수 있다. HTML(HyperText Markup Language)은 컴퓨터 웹 페이지를 작성하는 데 사용하는 마크업 언어로, 계층적인 구조의 태그들로 이루어져 있다. 크롤링을 위해서는 웹의 기본적인 구조를 알아야하며, 원하는 태그를 찾아서 데이터를 추출하는 경우가 많기 때문에 사진을 통해 간단하게만 HTML을 배워보자. (웹 페이지의 구조와 내용은 HTML 태그로 작성하지만, 웹 페이지의 모양과 행동, 응용프로그램은 CSS/JavaScript로 작성되는 것을 알고 있으면 좋을 것 같다)


크롬을 기준으로 「도구 더보기」 - 「개발자 도구」를 클릭하면 HTML 구성을 쉽게 확인할 수 있으며, 쉽게 F12를 눌러도 확인가능하다.


웹 크롤링은 수집하려는 부분을 포함하는 HTML 요소를 찾는 것이 매우 중요하다. 어떤 내용들이 들어가는지, 자주 볼 수 있는 태그는 어떤 것들인지 알고 이제 직접 크롤링을 시도해보자.
정적 크롤링을 직접 해보자!
먼저, 정적 크롤링에 대해서 실습해보자. 정적 크롤링은 Requests와 BeautifulSoup 패키지를 활용하며 https://www.pythonscraping.com/pages/page3.html 사이트의 제목과 설명을 긁어오는 실습을 해보자.


해당 페이지는 크롤링 실습을 위해 아주 잘 구성된 html 페이지기 때문에 F12 단축키를 눌러 이렇게 잘 짜여진 HTML을 확인해볼 수 있다. 태그명은 tr, 속성명은 class, 속성값은 gift 인 것을 알 수 있다.
#설치가 안 되어 있을 경우
#pip install requests
#pip install beautifulsoup4
# requests 패키지 가져오기
# BeautifulSoup 패키지 불러오기. bs로 이름을 간단히 만들어서 사용
import requests
from bs4 import BeautifulSoup as bs
# 가져올 url 입력
url = "https://www.pythonscraping.com/pages/page3.html"
# requests의 get함수를 이용해 해당 url로 부터 html이 담긴 자료를 받아옴
response = requests.get(url)
# html parser를 이용해 text 형태로 저장해보자.
soup = bs(response.text, 'html.parser')
soup를 출력하면, 다음과 같이 해당 url의 html 정보가 모두 나오는 걸 확인할 수 있다. 여기서, 파싱의 개념을 잠시 짚고 넘어가자면, 파싱은 매우 길고 정신없는 html 문서를 잘 정리되고 다루기 쉬운 형태로 만들어 원하는 것을 가져올 수 있도록 해준다.
자, 이제 원하는 값만 가져와보자. 원하는 요소를 찾는 beautifulsoup의 함수는 find()와 find_all()이 있다. fiind는 매칭되는 첫 번째 태그 하나만 찾는 것이고, find_all은 매칭되는 태그를 모두 다 찾는다. 두 함수 모두 괄호 안에 ("태그명", {"속성명":"속성값"})의 형태로 구성하거나 태그를 넣으면 된다. 목표 태그에 따라 작성하는 법은 다음과 같다.
##########################################
#목표 태그
<p class='속성1'>값1</p>
<div id='속성2'>값2</p>
##########################################
# 태그 이름으로 찾기
soup.find('p')
#태그 class로 찾기
soup.find(class_='속성1') #해당 방식에 _ 는 필수이다.
soup.find(attrs={'class':'속성1'})
#태그 id로 찾기
soup.find(id='속성2')
soup.find(attrs={'id':'속성2'})
#태그 이름과 속성으로 찾기
soup.find('p',class_='속성1')
soup.find('div','id'='속성2')
위에서 찾은 표의 값들을 find_all 함수를 이용하여 한 번 추출해보자.
scrap = soup.find_all('tr',{'class':'gift'})
scrap
find_all 함수는 이렇게 리스트 형태로 해당 태그/속성의 모든 값들을 가져온다. 리스트의 제일 앞 값을 가져와보자.
scrap[0]
자, 이제 td 태그 안에 있는 것들의 값만 잘 불러오면은 리스트 형태로 잘 저장할 수 있을 것 같다. find_all('td')를 활용해서 가져와보자.
scrap[0].find_all('td')
정말 마지막이다. Vegitable Basket을 불러오기 위해 get_text 기능을 활용해보자. 결과를 모두 출력하기엔 너무 비효율적이니 주석으로 결과값을 제공한다.
#1
scrap[0].find_all('td')[0]
#1 결과
<td>
Vegetable Basket
</td>
#2
scrap[0].find_all('td')[0].get_text()
#2 결과
'\nVegetable Basket\n'
#3
scrap[0].find_all('td')[0].get_text()[1:-1]
#3 결과
'Vegetable Basket'for 문을 사용하면 상품명을 모두 들고 올 수 있을 것 같다.
item_list=[scrap[i].find_all('td')[0].get_text()[1:-1] for i in range(len(scrap))]
print(item_list)
직접 코드를 실행해보면서 느꼈겠지만, html에 대한 이해와 코드를 작성했을 때 어떻게 결과가 출력되는지 계속 확인하는 과정이 필요하다. 이는 정적 크롤링뿐만아니라 동적 크롤링에도 해당하는 사항이며, 익숙해질 필요가 있다.
동적 크롤링을 직접 해보자!
이제, 동적 크롤링을 진행해보자. 동적 크롤링은 selenium 패키지를 이용하며, selenium3가 아닌 selenium4를 사용하니, version을 잘 확인해서 실습을 진행해보자. 실습으로 네이버 스마트 스토어의 HTML의 구조를 살펴보고, 상품 정보를 크롤링해보자.

먼저, 본 실습의 목표는 네이버 쇼핑에 '패딩'을 검색한 후, 네이버 페이가 가능한 상품 중 리뷰가 많은 순서로 상품 정보를 크롤링하는 것을 목표로 하겠다.
그 전에, 셀레니움4에서 값을 반환하는 find_element와 find_elements()에 대해 알아볼건데, find_element는 여러 개의 요소 중 첫 번째 요소의 위치를 반환하며, find_elemennts는 여러개의 요소를 list 형태로 반환한다. 사용법은 다음과 같다. (복수형도 사용방법이 같다)
driver.find_element(By.CLASS_NAME, "")
driver.find_element(By.ID, "")
driver.find_element(By.CSS_SELECTOR, "")
driver.find_element(By.NAME, "")
driver.find_element(By.TAG_NAME, "")
driver.find_element(By.XPATH, "")
driver.find_element(By.LINK_TEXT, "")
driver.find_element(By.PARTIAL_LINK_TEXT, "")이 외에도 get, get_attribute, send_keys 등 다양한 함수가 있으나 이는 실습을 진행하면서 알아보자.
먼저, selenium을 설치해서 버전을 확인하자.
#pip install selenium
import selenium
print(selenium.__version__)
기본 세팅은 다음과 같이 설정해주자. 네이버 쇼핑에서 검색창에 패딩만 검색한 상태로 두고 URL을 복사해두자.
#webdriver를 사용하기 위한 import
from selenium import webdriver
# selenium으로 매개변수 경로를 이용하기 위한 import
from selenium.webdriver.common.by import By
# selenium으로 크롬의 옵션을 조정하기 위한 import
from selenium.webdriver.chrome.options import Options
#ChromeDriver를 쉽게 불러오기 위한 import
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
# selenium으로 키를 조작하기 위한 import
from selenium.webdriver.common.keys import Keys
import timeoptions = Options()
options.add_experimental_option("detach", True)
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=options)해당 코드를 실행하면 chrome driver를 따로 설치하지 않아도 된다.
이제 앞에서 복사했던 url을 복사해서 driver.get 기능을 이용하여 이동해보자.
url = 'https://search.shopping.naver.com/search/all?adQuery=%ED%8C%A8%EB%94%A9&origQuery=%ED%8C%A8%EB%94%A9&pagingIndex=1&pagingSize=40&productSet=total&query=%ED%8C%A8%EB%94%A9&sort=rel×tamp=&viewType=list'
driver.get(url)
정상적으로 이동한 걸 볼 수 있다.
이제, 크롤러를 통해 움직이는 화면이 아니라 잠시 새로운 크롬 창을 하나 켜서 '네이버페이'와 '리뷰 많은순'을 클릭하는 과정을 진행해보자.

먼저, 네이버페이를 클릭하기 위해 네이버페이의 XPath를 불러오자. html의 xpath는 상대 경로와 절대 경로가 있는데, 절대 경로인 full XPath를 copy해서 클릭해보자. click은 find_element 뒤에 .click()만 붙여도 쉽게 할 수 있다.
driver.find_element(By.XPATH, "/html/body/div/div/div[2]/div[2]/div[3]/div[1]/div[1]/ul/li[3]/a").click()똑같은 방식으로 리뷰 많은 순 버튼을 클릭해보자.
driver.find_element(By.XPATH, "/html/body/div/div/div[2]/div[2]/div[3]/div[1]/div[1]/div[2]/div[1]/a[4]").click()
############################ 추가된 내용 ######################
처음에 패딩을 입력을 하고 시작했는데, 직접 입력하는 방식으로도 진행할 수 있다. 다음 코드를 활용해보자
driver.find_element(By.XPATH,"/html/body/div/div/div[1]/div[2]/div/div[2]/div/div[2]/form/div[1]/div[1]/input")
driver.click()
driver.send_keys('검색어')
driver.send_keys(Keys.ENTER)#############################################################
본격적으로 상품정보를 크롤링하기 위해 HTML 정보를 파악해보자.

product_info_area_xxCTi 클래스 안에 원하는 정보가 모두 담겨있는 걸 알 수 있다. 다음 코드를 통해 정보를 가져와보자.
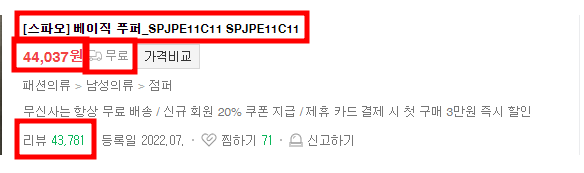
목표는 다음과 같으며, 다음과 같은 html로 구성되어 있다.




모두 CLASS NAME을 통해 값을 불러와보자.
names = []
prices = []
delivers = []
reviews =[]
for info in infos:
name = info.find_element(By.CLASS_NAME, 'product_title__Mmw2K').text
names.append(name)
price = info.find_element(By.CLASS_NAME, 'price_num__S2p_v').text
prices.append(price)
deliver = info.find_element(By.CLASS_NAME, 'price_delivery__yw_We').text
delivers.append(deliver)
review = info.find_element(By.CLASS_NAME, 'product_num__fafe5').text
reviews.append(review)
print(names[0],prices[0],delivers[0],reviews[0])
그러면, 이렇게 값이 제대로 저장된 것을 확인할 수 있다 :) 이제, 해당 값들을 데이터프레임화시켜보자.

동적 크롤링의 실습은 여기서 마치겠다.
동적 크롤링은 이 외에도 스크롤을 하거나, 페이지를 넘기는 등의 여러 작업을 수행할 수 있으며, 더 많고 복잡한 html 구조를 이해하는 연습도 꾸준히 필요하다.
그럼, 이상으로 크롤링에 대한 B to P에 대해 모두 마칩니다.